OpenAI GPT-3: Everything You Need to Know by Kindra Cooper
OpenAI GPT-3: Everything You Need to Know

In this article
OpenAI’s latest model has gone viral again. Much like its predecessor, there is no stopping to the buzz that OpenAI’s latest model GPT-3 is creating around the internet. As experts praise the model for its intuitive capabilities which range from writing articles to generating code, many experts including the founder of OpenAI have called out the hype “way too much”. The timing of the release lines up OpenAI’s new business model of commercialising its AI through API. Unarguably, OpenAI GPT-3 draws the attention of data science enthusiasts towards the idea of artificial general intelligence taking shape. In this blog, we present the various aspects of GPT-3, from the details of building blocks to the performance of the model and the possibilities of what all it can do.
OpenAI GPT-3: What is GPT-3?
Generative Pre-trained Transformer 3 (GPT-3) is a language model that leverages deep learning to generate human-like text (output). Not only can it produce text, but it can also generate code, stories, poems, etc. For these capabilities and reasons, it has become such a hot topic in the area of natural language processing (NLP- – an essential sub-branch of data science).
GPT-3 was introduced by Open AI earlier in May 2020 as a successor to their previous language model (LM) GPT-2. It is considered to be better and bigger than GPT-2. In fact, with around 175 Billion trainable parameters, OpenAI GPT-3’s full version is the largest model trained so far when compared to other language models. This 72-page research paper** describes in great detail the features, capabilities, performance and limitations of the model.
**We will refer to the research paper as “the paper” in our blog at multiple places.
In this blog, we have included some illustrations directly from the paper and focused on some key highlights so as to save you from having to read through the paper.
GPT-3 is a very large language model. Given some input text, it can probabilistically determine what tokens from a known vocabulary will come next. Before we go ahead and see what makes GPT-3 so special, lets first understand what is a language model?
What are Language Models (LMs)?
Simply put, language models are statistical tools to predict the next word(s) in a sequence. In other words, language models are probability distribution over a sequence of words. Language models have many applications like:
- Part of Speech (PoS) Tagging
- Machine Translation
- Text Classification
- Speech Recognition
- Information Retrieval
- News Article Generation
- Question Answering, etc.
A popular encoding method used in NLP is Word2Vec which was developed in 2014. The real boost to language models came in 2019 with the arrival of the “transformer”. You can read more about “attention” and “transformer” here in the paper in which it was proposed. Or leave us feedback and we will cover it for you in one of our blogs!
What Makes OpenAI GPT-3 Different?
The first thing that GPT-3 overwhelms with is its sheer size of trainable parameters which is 10x more than any previous model out there.
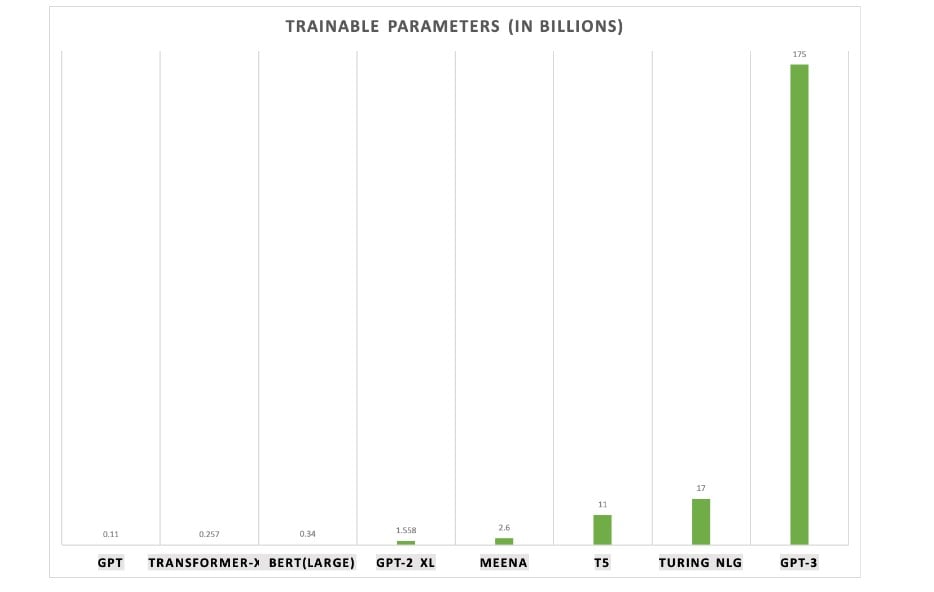
In general, the more parameters a model has, the more data is required to train the model. As per the creators, the OpenAI GPT-3 model has been trained about 45 TB text data from multiple sources which include Wikipedia and books. The multiple datasets used to train the model are shown below:
| Dataset | Quantity (tokens) | Weight in training mix | Epochs elapsed when training for 300B tokens |
| Common Crawl (filtered) | 410 billion | 60% | 0.44 |
| WebText2 | 19 billion | 22% | 2.9 |
| Books1 | 12 billion | 8% | 1.9 |
| Books2 | 55 billion | 8% | 0.43 |
| Wikipedia | 3 billion | 3% | 3.4 |
Common Crawl corpus contains petabytes of data collected over 8 years of web crawling. The corpus contains raw web page data, metadata extracts and text extracts with light filtering.
WebText2 is the text of web pages from all outbound Reddit links from posts with 3+ upvotes.
Books1 & Books2 are two internet-based books corpora.
Wikipedia pages in the English language are also part of the training corpus.
The third column in the table “Weight in training mix” refers to the fraction of examples during training that are drawn from a given dataset.
A major issue in training models and in particular such large training models with so much data from the internet is that these models have the capacity to memorise the content and then contaminate downstream tasks like testing as they might have already seen the data. Though the creators of GPT-3 took some measures to avoid the training and test data overlaps but a bug in the filtering caused some of the data to leak. As mentioned in the paper, the team could not retrain the model due to the high cost associated with the training.
OpenAI GPT-3 Architecture
The GPT-3 is not one single model but a family of models. Each model in the family has a different number of trainable parameters. The following table shows each model, architecture and its corresponding parameters:
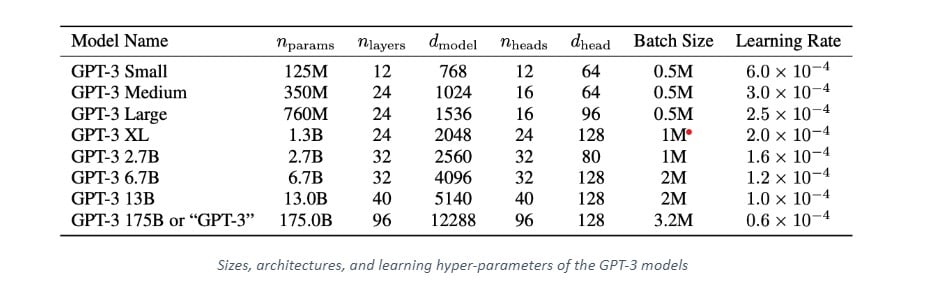
In fact, the OpenAI GPT-3 family of models is based on the same transformer-based architecture of the GPT-2 model including the modified initialisation, pre-normalisation, reverse tokenisation, with the exception that it uses alternating dense and sparse attention patterns.
The largest version GPT-3 175B or “GPT-3” has 175 B Parameters, 96 attention layers and 3.2 M batch size.
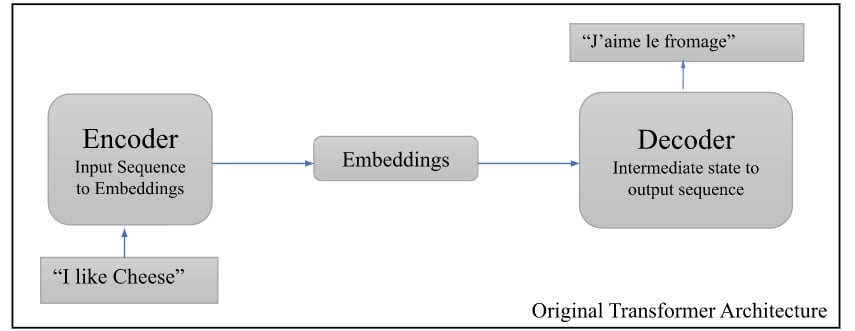
Shown in the figure above is the original transformer architecture. As mentioned before, OpenAI GPT-3 is based on a similar architecture, just that it is quite larger. While language models like BERT use the Encoder to generate embeddings from the raw text which can be used in other machine learning applications, the GPT family use the Decoder half, so they take in embeddings and produce text.
Accuracy / Performance / Numbers of OpenAI GPT-3
The various tasks that any language model can perform depend on how it is fine-tuned/updated. With GPT-3 many of the NLP tasks discussed earlier can be done without any fine-tuning, gradient or parameter updates which makes this model Task-Agnostic. So OpenAI GPT-3 can perform tasks with very few or no examples/demonstration (or shots as they are better known). Before we dive into the numbers lets first understand the concept of Zero/One/Few shot tasks with respect to the model and see how one can interact with the model using a few examples.

Above figure shows the three settings in which GPT-3 can perform the task of translating from English to French.
The Few-shot (FS) setting is kind of similar to how we go about training a machine learning model where we give some inputs and corresponding outputs to a model and then expect the model to perform on an unseen input. However, the difference here is that unlike a normal ML algorithm, the model does not do any weight updates. It just infers on the basis of the “shots” that it has been fed. One typically feeds in between 10-100 shots for one such setting (as per the paper).
One-Shot (1S) setting is the same as FS except that only one example/demo/context is fed to the model in addition to the last context(which is the task).
Zero-Shot (0S) is when there is no context allowed except for the last (which is the task). This kind of setting is “unfairly hard” as it could be difficult for even humans to understand what the task is with no example or demonstration.
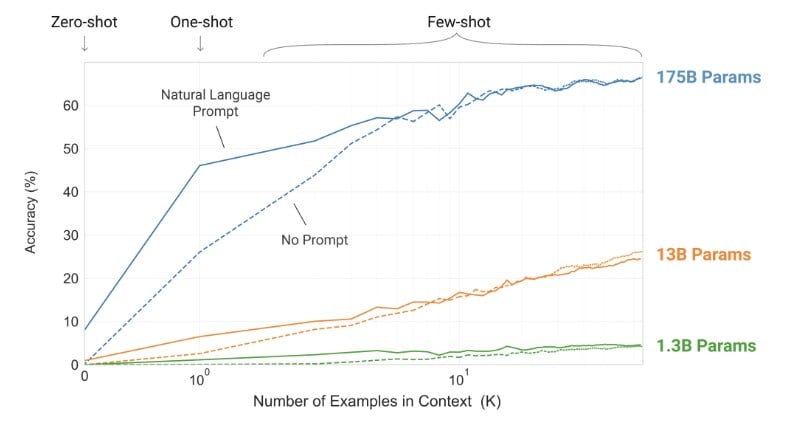
The above image shows the accuracy of the OpenAI GPT-3 model while performing the Zero-shot, One-shot and Few-shots tasks along with the number of parameters and shots for a simple task to remove random symbols from a word. Now, let’s have a look at how the models (175B params to 125M params) perform at some well known (benchmarked) tasks. All results cited (quoted) from the paper.
OpenAI GPT-3 Language Modelling
“Our largest model sets a new SOTA on PTB by a substantial margin of 15 points, achieving a perplexity of 20.50. Note that since PTB is a traditional language modelling dataset it does not have a clear separation of examples to define one-shot or few-shot evaluation around, so we measure only zero-shot.”
The team calculated 0S perplexity on the Penn Tree Bank dataset.
LAMBADA
The LAMBADA dataset basically tests a model’s capability to predict the last word of sentences which require reading a paragraph of context.
“…in a zero-shot setting GPT-3 achieves 76% on LAMBADA, a gain of 8% over the previous state of the art.”
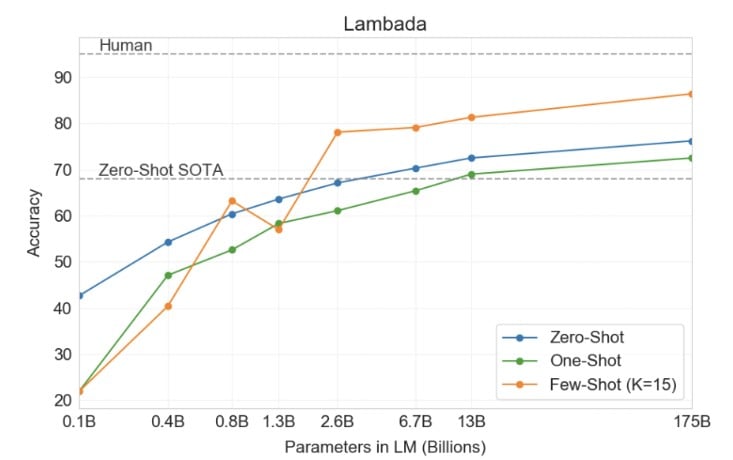
“…GPT-3 2.7B outperforms the SOTA 17B parameter Turing-NLG in this setting (FS), and GPT-3 175B advances the state of the art by 18%…”
HellaSwag
“The HellaSwag dataset involves picking the best ending to a story or set of instruction. GPT-3 achieves 78.1% accuracy in the one-shot setting and 79.3% accuracy in the few-shot setting, outperforming the 75.4% accuracy of a fine-tuned 1.5B parameter language model but still a fair amount lower than the overall SOTA of 85.6% achieved by the fine-tuned multi-task model ALUM.”
StoryCloze
The StoryCloze 2016 dataset involves selecting the correct ending sentence for five-sentence long stories. “Here GPT-3 achieves 83.2% in the zero-shot setting and 87.7% in the few-shot setting (with K = 70). This is still 4.1% lower than the fine-tuned SOTA using a BERT based model [LDL19] but improves over previous zero-shot results by roughly 10%.”
OpenAI GPT-3: Closed Book Question Answering
This task tests the ability of OpenAI GPT-3 to answer questions about broad factual knowledge. GPT-3 was tested on three different QA datasets. The results for the same are shown in the table below:
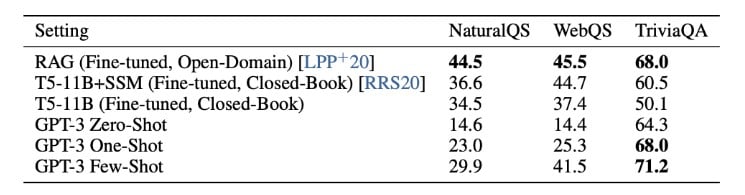
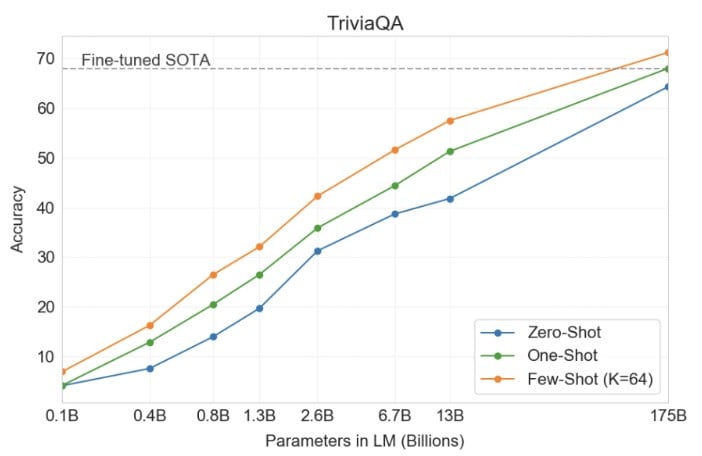
The figure above shows GPT-3’s performance on the TriviaQA dataset. It can be observed how the performance grows with size and how 1S and FS settings beat 0S and match + exceed the SOTA on the task.
OpenAI GPT-3: Language Translation
Although GPT-3’s training data comprised of > 90% English text it did include some foreign language text. Following graph (taken from the paper) summarises the performance of GPT-3 on the language translation task.
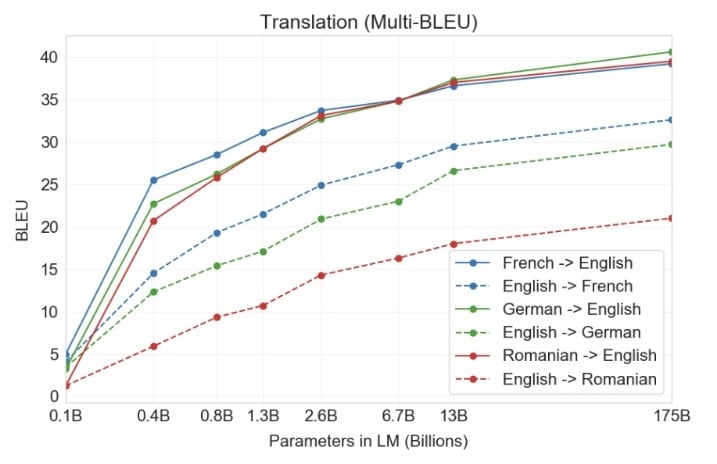
“For the three input languages studied, GPT-3 significantly outperforms prior unsupervised NMT work when translating into English but underperforms when translating in the other direction.”
Winograd-Style Tasks
The Winograd Schemas Challenge involves determining which word a pronoun refers to, when the pronoun is grammatically ambiguous but semantically unambiguous to a human.
“On Winograd GPT-3 achieves 88.3%, 89.7%, and 88.6% in the zero-shot, one-shot, and few-shot settings respectively, showing no clear in-context learning but in all cases achieving strong results just a few points below state-of-the-art and estimated human performance.”
Get To Know Other Data Science Students

George Mendoza
Lead Solutions Manager at Hypergiant

Leoman Momoh
Senior Data Engineer at Enterprise Products

Isabel Van Zijl
Lead Data Analyst at Kinship
Common Sense Reasoning
Three datasets were considered for this task. The first dataset PhysicalQA (PIQA) asks common sense questions about how the physical world works and is intended as a probe of grounded understanding of the world. “GPT-3 achieves 81.0% accuracy zero-shot, 80.5% accuracy one-shot, and 82.8% accuracy few-shot (the last measured on PIQA’s test server). This compares favourably to the 79.4% accuracy prior to the state-of-the-art of a fine-tuned RoBERTa.”
There are few more results mentioned in the paper for tasks like reading comprehension, SuperGLUE, NLI, synthetic and qualitative tasks (arithmetic, word scrambling and manipulation, SAT analogies, News article generation, learning and using novel words, correcting English grammar). Let’s pick up the most interesting task of News Article Generation.
News Article Generation
The release of GPT-2’s largest model was briefly on hold due to the controversy of it being capable of generating fake news. GPT-3 model was able to generate news articles that are practically indistinguishable from the real ones. One of the experiments showed that for the 175B model, humans were able to distinguish fake articles with only 52% accuracy.
Here are some of the examples of the fake news article generated by GPT-3 along with the accuracy that the human participants achieved in being able to distinguish it.


The plot below shows the human ability to detect model generated fake news articles.
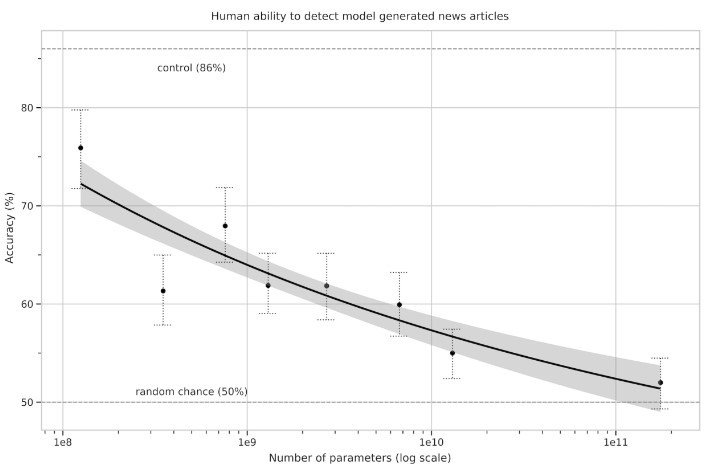
It can be observed from the plot above that the ability to distinguish fake article decreases as the model size increases.
How Can We Get Our Hands on the Model?
You can’t simply download the model or train it on your own even if you have the infrastructure. OpenAI has built an API which is accessible through a waiting list. You can visit their site and join the waiting list. In fact, you can go to the demo section of https://beta.openai.com and try out some demos yourself to get a fair idea of how some of the use-cases work.

If you select the Q&A task and click on “See cached response” button, you will get the following result:
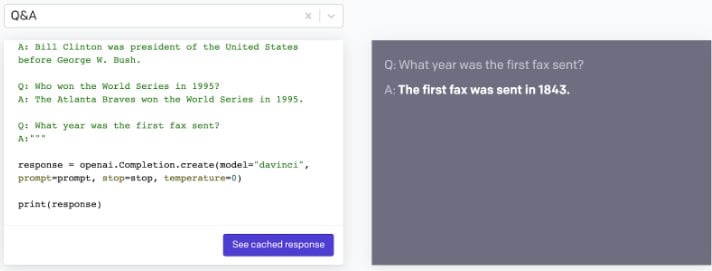
So if you were to do a task like the one shown above, you would need to write a code similar to the one shown below:
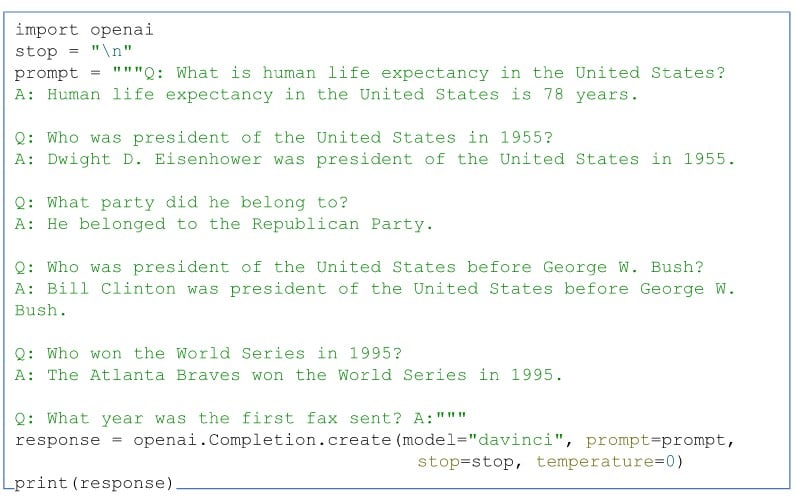
As you can observe in the code snippet above, the API is provided with 5 contexts and the last Q is the task that the model needs to complete. It needs to predict what words will follow ‘A:’.
Since the waiting list is just too long and it could be a while before you get your hands on your own API key, we have some examples gathered from the web on how machine learning enthusiasts and data scientists are using the model for different applications.
Natural Language to SQL generation
Creating ToDo List Apps (and other apps)
Python Code Generation from Natural Text
You will get many more such examples on the internet of how enthusiasts who have access to the API are creating more such applications with GPT-3.
Limitations of OpenAI GPT-3
The creators of GPT-3 themselves accept that the model has its weaknesses and does commit silly mistakes. In particular, it does not perform well on text synthesis tasks like repetitions, contradictions, coherence loss over long passages, etc. However, this is not too different from other language models. The architecture also introduces a fundamental limitation on the model. The GPT-3 model is an autoregressive language model and not a bidirectional one (like BERT). So GPT-3 is more suited for tasks which are “in-context” learning-based and not the ones which depend on “fine-tuning”.
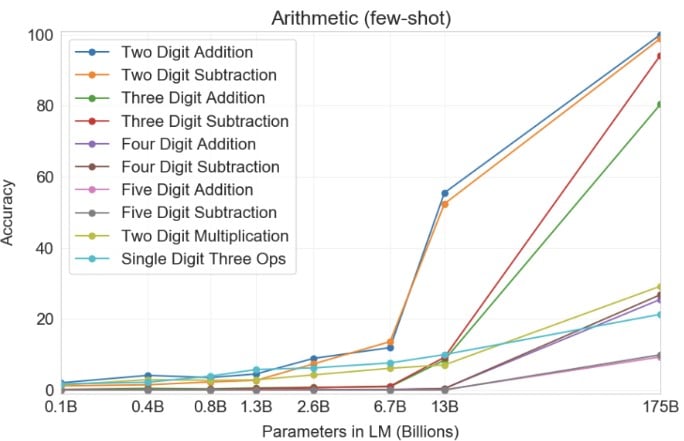
Shown below are the accuracy results of GPT-3 models on arithmetic tasks. It can be seen how smaller models perform poorly on simple tasks of even single-digit or double-digit arithmetic and accuracy on 4-digit (and above) arithmetic is low.
Summary
To summarise:
- GPT-3 is a very large language model (the largest till date) with about 175B parameters.
- It is trained on about 45TB of text data from different datasets.
- As such the model itself has no knowledge, it is just good at predicting the next word(s) in the sequence. It is not designed to store or retrieve facts.
- It produces more fluent and human-like text outputs.
- You don’t need task-specific datasets to accomplish a task using GPT-3. It is “Task-Agnostic”.
- You cannot download or retrain the model. You need an API key (can get by joining the waitlist). It has “closed-API” access.
- It is good mostly for English language tasks.
- Longer outputs from the model tend to degrade.
- The outputs can be biased and abusive.
- There are known contaminations in the benchmark experiments which have been called out clearly in paper.
Even with the API still in the closed-beta state and a long waiting list, the AI and data science community is quite excited about the potential and power of the model and how artificial general intelligence (AGI) is evolving. However, if we are to learn from the issues associated with GPT-2 we need to be more careful and responsible with what we create using this model.
Since you’re here…Are you a future data scientist? Investigate with our free step-by-step guide to getting started in the industry. When you’re ready to build a CV that will make hiring managers melt, join our 4-week Data Science Prep Course or our Data Science Bootcamp—you’ll get a job in data science or we’ll refund your tuition.